Archive
There are 132 069 776 transformation semigroups on 4 points…
…and here they are. If it is not clear why this is so exciting, then this little note may be helpful.
So slightly more than 132 million – up to conjugation, of course. The grand total is 3 161 965 550, but under normal circumstances we are only interested in the conjugacy class representatives.
How do we know? We enumerated all subsemigroups of 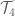
The above archive is a bit of a surprise package, the file size is 1.2GB and you need 9.2GB of disk space when uncompressed. The semigroups are classified according to their size and the numbers of 
T4_S042_L006_R013_D003.gens
then you can fire up GAP and the Semigroups package and use the ReadGenerators function to load the semigroups, or rather the generating sets for them. Nice and easy, isn’t it? Well, we are planning to make this a bit more accessible with some web interface magic, hopefully in the near future.
For the above example, the file contains only one semigroup, stored in exactly 42 bytes. 🙂
If the required file doesn’t exist, then there is no degree 4 transformation semigroup with the specified numbers. Or we made a mistake at some point.
Speaking of that, we believe that the archive has no errors and omissions. The enumeration uses simple graph-search algorithms, so the correctness is easy to see. However, with real-world actual physical computers, you can never know. Please let us know if something looks suspicious.
Also lease let us know if you find this database helpful/interesting/exciting/useful.
Here is a talk summarizing the project (in case you can put up with my heavy accent, the audio quality gets better once the mic is switched on).
Announcement
Computational semigroup theory is a growing field within computer algebra and a lot is happening there at the moment (many software packages are on the brink of a new release). But the progress is done almost without any publicity. Therefore the aim of this site is to collect up-to-date information regarding new results, new releases of software packages. Also, interviews with mathematicians using the computer in their work and with developers (yes, most of the time the same person) will be posted here, so you can see the faces and learn something about their personalities. Thus next time at a conference you will have no trouble finding the person you want to talk to.
